© IE Online Media Services Pvt Ltd

 Based on the benchmarks, the model has outperformed GPT-4o, Claude Sonnet 3.5. (Image: Kimi.AI)
Based on the benchmarks, the model has outperformed GPT-4o, Claude Sonnet 3.5. (Image: Kimi.AI)The AI arms race is heating up with China dominating the conversations around the world. Just when the AI community was coming to terms with the capabilities of DeepSeek’s DeepSeek-R1, which rivals the OpenAI-o1 model, there is another player claiming to be as good, if not superior to, o1. The era of Chinese AI models has officially begun with DeepSeek, and now we have Kimi k1.5 which has outshone OpenAI’s GPT-4o and Claude 3.5 Sonnet on some key benchmarks.
Kimi k1.5 is the latest model released by Beijing-based AI startup Moonshot AI. The newly released Kimi reportedly matches or even outperforms the OpenAI-01 model. The O1 model has been designed to spend more time thinking before it responds, and it is capable of solving more complex problems. Reportedly, Kimi has outperformed o1 in areas like mathematics, coding, and the ability to understand text and visual inputs like photos and videos, which makes it multimodal, unlike DeepSeek-r1. Just like DeepSeek’s AI models, Kimi is built at a fraction of the cost required to build frontier AI models in the US. Kimi k1.5 has been released through Kimi.ai, and it has been hailed as the first true competitor to o1.
Reportedly, Kimi k1.5 is not just an AI model; it is being touted to be a big leap in reinforcement learning (RL) and multimodal reasoning. The model has the ability to combine visual data, text, and code to solve complex problems. Based on the benchmarks, the model has outperformed GPT-4o, Claude Sonnet 3.5. The team behind Kimi has released a detailed report that establishes how the model has achieved its breakthrough along with challenges.
In essence, Kimi k1.5 is a multi-modal large language model that has been trained using reinforcement learning methods. Considering that it can process multiple formats of data, Kimi is a versatile model with multifaceted applications. While conventional AI models depend on static datasets, Kimi learns through exploration and rewards. This process, reportedly, enhances its ability to reason through and solve complex problems.
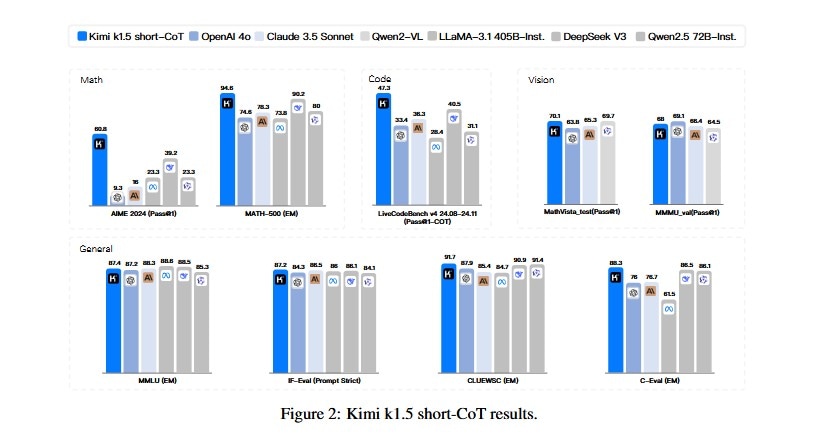 Kimi K1.5 Benchmark performance.
Kimi K1.5 Benchmark performance.
Kimi k1.5 has scored 96.2 on MATH 500, which is better than OpenAI’s GPT-4 variants. It scored 77.5 on AIME (math benchmark) and 94th percentile on Codeforces (coding-related problems). The model also surpassed GPT-4 and Claude 3.5 Sonnet on numerous benchmarks by up to 550 percent. Contrasted with its US peers like GPT-4 and Claude models, Kimi surpasses them in reasoning and problem-solving abilities. The model is efficient with long-context tasks and complex mathematics. However, the reliability of benchmark test scores is often questioned as AI companies conduct the assessments on their own and publish the results.
As mentioned earlier, Kimi uses RL techniques to enhance its ability to make decisions; it improves itself by exploring and refining solutions. The model uses the Chain of Thought approach, meaning it breaks complex problems into smaller steps to improve its reasoning. Based on the research paper, the model is capable of handling long context windows—up to 128k tokens—and this allows it to understand and generate responses based on vast information. Since it can process and reason across text and images, Kimi can be used for tasks like text-image analysis and solving problems requiring visual input. When it comes to efficiency, the model uses methods known as partial rollouts and length penalties that essentially reuse previous outputs and avoid lengthy responses.